
在数据中心、智算中心的复杂网络环境中,业务变慢、故障难定位、性能瓶颈不透明等问题长期困扰着运维团队。传统依赖主机 Agent 的监测方式,不仅侵入性强、覆盖范围有限,还无法实现故障后的回溯复盘。NetInside 基于流量旁路采集监测技术打造的网络应用性能监测系统,以零侵入、全流量、可回溯的核心优势,为现代网络性能管理提供了全新解决方案。
一、传统监测困局:为何常规方案难以适配复杂场景?
随着业务架构向分布式、云原生、HPC 智算方向快速演进,传统监测工具的局限性日益凸显。这类工具大多需要在业务主机安装 Agent,不仅可能占用系统资源、影响核心业务稳定性,还只能采集少量离散指标,无法捕捉完整的业务流量链路。当数据中心的东西向流量占比超 80%、智算中心的训练流量与调度流量交织时,传统工具往往陷入“数据断层”,既无法实现跨层级分析,也不能在故障发生后“重放”现场,导致问题排查效率低下。
对于金融交易网络、能源行业网络等关键场景而言,毫秒级时延波动、隐性拥塞等问题都可能引发严重损失。而传统方案要么无法精准识别这类隐性问题,要么在部署过程中存在安全合规风险,难以满足行业对稳定性和安全性的双重要求。
二、核心突破:旁路采集+全流量分析的技术革新
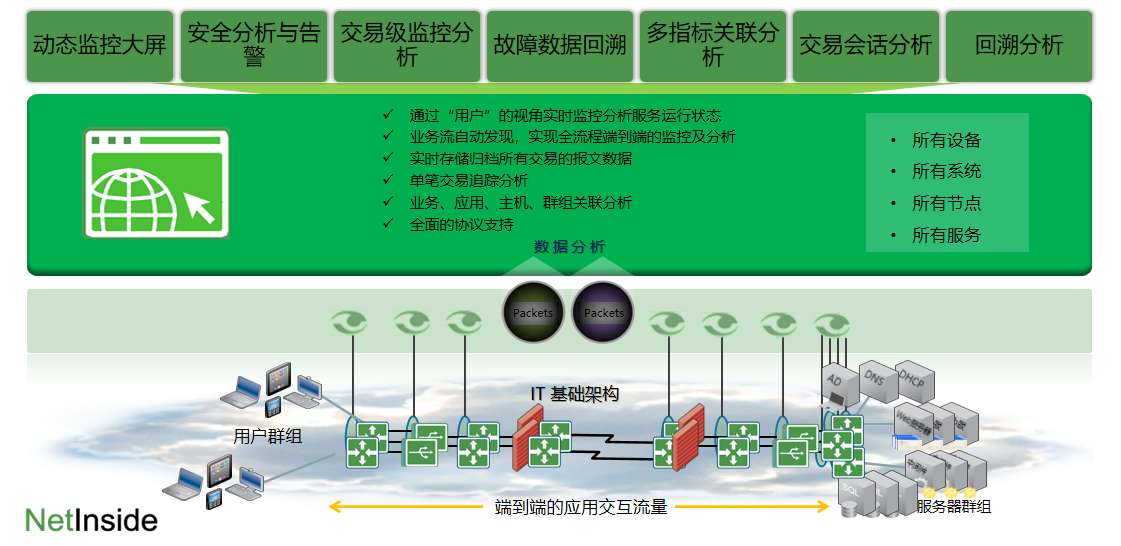
NetInside 摒弃了传统 Agent 部署模式,采用旁路分析(bypass monitoring)技术路线,通过交换机 SPAN 镜像、TAP网络分流器、旁路交换机等方式采集流量,整个过程不改动原业务链路、不触碰业务主机,实现真正的零侵入部署。这种采集方式不仅能完整捕获经过交换机的所有业务流量,包括正常访问、异常请求和隐藏会话,还支持分钟级、小时级甚至天级的历史流量存储,为故障回溯提供了坚实基础。
在流量解析层面,系统内置 L2-L7 深度协议解析技术,可覆盖 MAC/IP/TCP 等基础网络协议、HTTP/HTTPS 等应用协议、MySQL/Oracle 等数据库协议,以及 MPI 等 HPC 专属协议。解析后的字段将以结构化形式统一存储,包含源 IP、目的 IP、时延、响应时间等关键信息,为后续分析提供精准数据支撑。
结合智能运维(AIOps)引擎,系统能够基于 7×24 小时历史数据构建动态性能基线(baseline),自动识别指标突增、突降、波动等异常情况。通过慢事务检测、频繁失败模式识别、多节点路径分析等模型,还能快速定位故障根因,生成清晰的根因链,将平均故障定位时间(MTTD)缩短 80%。
系统架构图
三、全场景覆盖:从数据中心到关键行业的落地实践
数据中心全流量可观测
针对数据中心可观测解决方案的流量密集的特点,系统实现了南北向与东西向流量的全覆盖,可同时监测核心业务、支撑系统和后台服务的性能状态。通过自动绘制访问链路拓扑图,直观呈现客户端、负载均衡、应用服务器、数据库之间的时延分布,帮助运维团队快速锁定瓶颈环节。
智算中心性能优化
专为智算中心-HPC 网络解决方案定制的协议解析能力,可精准识别 MPI 消息传递、作业调度、节点心跳等流量类型。通过分析训练数据传输时延、节点通信状态,有效解决训练任务延迟、算力效率低下等问题,为 AI 模型训练提供稳定的网络环境支撑。
金融交易网络保障
在金融交易网络中,系统以微秒级时延监测能力,实时监控交易链路的响应时间、成功率等核心指标。结合 SLA 监控与智能告警功能,确保交易性能满足行业合规要求,同时通过故障快速回溯能力,最大限度降低异常交易带来的损失。
能源与政企系统监测
适配能源行业多站点分布式部署特点,系统采用“分布式采集+集中式管理”模式,统一监测发电厂、变电站等各站点的网络状态。针对政企系统,可实现多业务统一监测、峰值流量应对、故障责任界定等功能,保障政务服务、电力调度等关键业务的稳定运行。
四、技术优势:重新定义网络性能监测标准
- 零侵入安全部署:无需安装 Agent,不影响现网业务,特别适合对稳定性要求极高的核心生产环境;
- 全流量无死角覆盖:捕获所有经过交换机的业务流量,避免数据盲区,为分析决策提供完整数据;
- 强回溯故障复盘:支持历史流量重组与业务内容恢复,故障发生后可精准还原现场,提升复盘效率;
- 全协议适配能力:覆盖通用协议、数据库协议、行业专属协议,适配多场景业务需求;
- 全流量异常监测:自动化异常检测、根因分析与 KPI 预测,降低对资深运维人员的依赖,提升运维效率 60% 以上;
- 国产化合规适配:软硬件全面支持国产化操作系统、芯片与数据库,满足政企行业自主可控要求。
五、NetInside:深耕网络可观测领域的技术领航者
作为全流量旁路采集与网络应用性能监测领域的专业厂商,NetInside 深耕行业十余年,自主研发了 NPM 网络应用性能管理、全流量回湖分析系统-TTRA、可观测性分析平台等核心产品,形成了“采集-解析-分析-回溯-可视化”的全流程解决方案。
凭借稳定可靠的产品性能与专业的技术服务,NetInside 已服务中国人民银行、国家电网、大型商业银行、省级政务云等 100+ 关键客户,累计部署超 500 个采集节点,覆盖金融、能源、政务、运营商、制造业等多个行业。未来,NetInside 将持续投入深度协议解析、AIOps 算法优化、全流量存储技术等核心领域研发,助力更多用户实现“网络可观测、故障可定位、性能可优化”的运维目标。
六、常见问题解答
- Q:系统是否需要在业务主机安装 Agent?
A:不需要。系统通过交换机旁路镜像、TAP 光分路器等方式采集流量,不触碰业务主机,对现网无任何侵入性影响。
- Q:系统支持的最大采集带宽是多少?
A:单机支持万兆 / 25G/40G/100G 接口,多节点分布式采集模式下,可支持超 T 级总带宽采集,满足超大型智算中心需求。
- Q:能否解析加密的 HTTPS 流量内容?
A:支持解析 HTTPS 协议的 TLS 握手信息、SNI、证书信息,可识别业务指向与异常趋势;若需解析明文内容,需用户提供合法解密授权,严格遵循数据安全合规要求。
- Q:历史流量存储时长是多久?能否自定义?
A:默认存储 30 天历史流量,支持根据用户需求自定义存储策略,同时提供流量压缩与分级存储,降低存储成本。
- Q:系统是否支持与现有运维工具集成?
A:支持。提供标准 API 接口与 Prometheus exporter,可将指标、告警信息同步至 Zabbix、Prometheus 等工具,实现数据互通。
- Q:部署一套系统需要多长时间?
A:中小规模数据中心(单采集点)部署周期约 1-2 周;大型分布式采集场景约 3-4 周,具体视采集点数量与网络复杂度调整。